Batched Rendering with WebGL 1.0
WebGL has finally made it possible to exploit the performance of modern GPUs inside common Web pages. Still, the performance of a WebGL app will potentially be worse than for a comparable native desktop application. One major reason for this is that a Web browser must interpret all WebGL API calls and forward them to the system. (Chrome on Windows, for instance, does it using the ANGLE layer).
With this in mind, it is not surprising that the performance of any WebGL application is especially sensitive to the amount of API calls within each frame. One use case where this topic becomes important is the rendering of large scenes, consisting of hundreds or thousands of identifiable objects. A common trick is therefore to batch multiple draw commands together. This idea has already been described by the guys from Google in 2011 (see this video), and it has also been discussed by people developing WebGL engines, such as Three.js (see this ticket). However, implementing a batched rendering system inside a 3D graphics engine built on WebGL 1.0 is not trivial, and it has some important implications. During the rest of this article, I hope to summarize the most important aspects, and I'll also come up with two demos, one with batched rendering and one without.
A Simple WebGL Rendering Pipeline
The probably most common way of rendering a scene suggests that there is exactly one draw call per scene object: The vertex shader will use a matrix uniform variable to transform each vertex of the current object to world space, and the fragment shader will use a set of uniform variables to compute the shading for each fragment of the object.
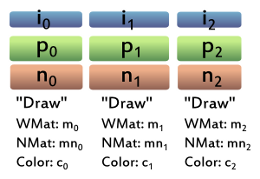
A very basic example could be three different objects, each having its own index buffer, vertex position buffer, normal buffer, and so on. In Figure 1, those buffers are labeled with "i" for index, "p" for position, and "n" for normal. The corresponding draw command for each object uses a separate world matrix and color.

For this simple example, the code to draw all objects of the whole scene and the corresponding shaders could could look like this:
Draw Code (One Draw Per Object):
for (var i = 0; i < sceneObjects.length; ++i) {
bindBuffers(sceneObject[i]);
updateUniforms(sceneObject[i]);
drawObject(sceneObject[i]);
}
attribute vec3 a_position;
uniform mat4 u_mvpMat;
void main() {
gl_Position = u_mvpMat * vec4(a_position, 1.0);
}
uniform vec3 u_materialColor;
void main() {
gl_FragColor = vec4(u_materialColor, 1.0);
}
Of course, everything is simplified a bit, to keep the example concise (no shading, for example). Still, what is important in this context is how the basic "workflow" of drawing and shading is organized: As can be seen in the example draw code, each object requires a separate bind call, separate uniform updates, and a separate draw call. This is quite expensive, so let's see what we can do about it.
Batching Draw Calls
When drawing multiple instances of the same object, we only need to bind the buffers for the corresponding object once. This way, we can already save some buffer bind calls, given that we first sort the scene object instances by the buffers they use. Another optimization is to concatenate the geometry of multiple (also different) objects to a single, larger buffer. We then only need to bind this buffer once per frame, and we could still draw each object separately, using a corresponding offet when executing gl.drawArrays or gl.drawElements.
Reducing the number of uniform updates takes a bit more work. We can see that the above vertex shader needs a separate model-view-projection matrix for each object. For multiple subsequent objects, this matrices could be batched together into a uniform array, but this approach requires some mechanism inside the shader to still be able to identify which object we are currently drawing. This could be solved by another uniform that servers as an index into the matrix array, which could especially make sense if there is more than one uniform to be batched. However, there is also another way which we will go now: To identify to which object each vertex belongs during rendering, we will use per-vertex object IDs as an additional attribute. This object ID is then used inside the vertex shader to pick the correct entry out of the uniform array. Current desktop OpenGL versions provide a built-in variable gl_VertexID for the vertex shader, which we could use to somehow determine which object our vertex belongs to. But since this feature is not required for WebGL 1.0 implementations, we cannot rely on it, so we have to work with the separate ID buffer for now.
Similar to the vertex shader, the above fragment shader needs one uniform update per object. To reduce this, we can use a texture to store the colors for some (or even all) objects in the scene. The vertex ID can then be passed to the fragment shader and used to index into this texture.
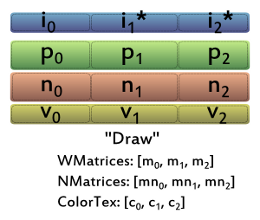
So far, we have considered reducing buffer binds and uniform updates. But what really will make our batched rendering much faster than the non-batched version is the reduction of draw calls. Even for desktop OpenGL applications, reducing draw calls is probably one of the most important goals (see, for instance, this blog post). Luckily, as shown in Figure 2, there is no piece of information left that would need to be updated per object during a draw, as we have stored everything in array-like structures that can directly be accessed from the shaders during rendering. So, we can now simply render a whole batch of objects with a single call to gl.drawArrays or gl.drawElements. Still, if we use gl.drawElements (i.e., indexed rendering), we will first have to adapt the indices to the vertex data for all but the first objects within each batch. We'll also have to keep an eye on the 16 bit index limit of WebGL, so we might at maximum draw objects that together have 65,535 vertices or less within a single draw.
for (i = 0; i < drawBatches.length; ++i)
{
bindBuffers(drawBatches[i]);
updateUniforms(drawBatches[i]);
drawBatch(drawBatches[i]);
}
attribute float a_idoff;
attribute vec3 a_position;
uniform mat4 u_mvpMat[16];
varying float v_idoff;
void main()
{
int idx = int(floor(a_idoff));
gl_Position = u_mvpMat[idx] * vec4(a_position, 1.0);
v_idoff = a_idoff;
}
uniform sampler2D u_materialColorSampler;
const float halfPixelSize = 0.5 * (1.0 / 16.0);
varying float v_idoff;
void main()
{
float vertexIDTexCoord = v_idoff / 16.0 + halfPixelSize;
vec3 materialColor = texture2D(u_materialColorSampler, vec2(vertexIDTexCoord , 0.5));
gl_FragColor = vec4(materialColor, 1.0);
}
At a first glimpse, the draw code looks pretty similar to the previous version. But as we are, this time, iterating over the number of batches instead of the number of scene objects, we have significantly less iterations, and hence significantly less draw calls. In this example, a single batch is able to hold up to 16 scene objects (regarding this number, see the discussion at the end of the article).
We can see in the vertex shader that we have now grouped the matrices of the 16 objects within each batch together, so they are now represented as a single matrix array inside the shader. The vertex and fragment shaders are also using a new variable, entitled idoff. This variable represents the offset of each object from the beginning of the batch (or the index, inside the batch, if you like it this way).
In a similar fashion to the matrix array being used inside the vertex shader, a 1D texture is used inside the fragment shader to look up the color of the corresponding object. To access that texture, a texture coordinate is computed from the idoff variable.
Performance
If you compare the simple and the batched version of the demo, you should hopefully be able to notice that the batched version renders much faster. I have made a small comparison for my desktop machine and plotted the results in Figure 3. My test machine was running Chrome 40 on Windows 7, and it was using a GTX 550 Ti GPU.
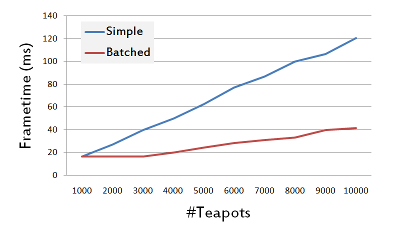
As can be seen in the results for a the first numbers of teapots, both curves start around the 16ms mark. This is due to vsync being enabled, so the framerate was any way capped at 60 FPS. I chose the number of 1,000 teapots as a starting point for plotting, since it was approximately the point where the simple, non-batched version became slower than this value. When drawing 10,000 teapots, the simple version renders with a frametime of around 120 ms (~8 FPS), while the batched version renders with a frametime of about 41 ms (~24 FPS). As both versions of the demo are rendering exactly the same number of triangles for a given number of teapots, it can be seen that, at least for the simple version, the number of draw calls is the actual bottleneck for rendering.
Discussion
Why Teapots, and why duplicate the data so often?
Maybe you have already asked yourself that question. One answer would be that the purpose of the demo was actually to pretend that there was independent data for thousands of objects, there just weren't that many at hand when demo was created ;-) As the batched version copies the data of each teapot any way, there is actually no difference to using thousands of completely different objects. Besides that, since the teapot mesh is relatively small, it is also well-suited to illustrate a draw bottleneck.
On the other hand, there are also a lot of applications where there is a massive re-use of the same geometry at multiple places. If we would, for example, want to implement a glyph-based 3D visualization, copying (at least index) data for each of the instances inside a batch is clearly a waste of memory. On the other hand, with WebGL 1.0, this seems the only way to keep the number of draws low, and at the same time ensure that you can manipulate all of your instances independently. Luckily, with WebGL 2.0, instanced rendering becomes possible. This will solve the problem of creating mesh data copies and maintaining a separate vertex attribute for IDs, when instantiating the same mesh a lot of times.

How can we hide / show single objects within a batch?
You have probably noticed the additional two buttons in the batched version of the demo, which enable you to highlight or hide single (random) teapots. Both of these do basically the same thing, they manipulate the RGBA color inside the texture used for the object colors. The button which hides teapots does so by setting the alpha channel of the corresponding texel to zero, which will cause fragments to be discarded inside the shader during rendering.
This solution, using a discard command, is known to be an expensive operation, for various reasons. One is that the GPU cannot employ an early z-test if the fragment shader dynamically decides to make fragments transparent, or to discard them. If a target application has more complicated shaders and a larger viewport, it might become fragment limited at some point, so it could make sense to avoid fragment generation whereever possible. In that case one could, for example, discard vertices by transforming them to a position where they always get clipped.
Why did we just use a batch size of 16?
At this point, you might wonder about the fixed batch size of 16 objects per draw. The reason is simply that shaders are allowed to use a maximum number of uniform vectors, which is determined by the GPU architecture. For WebGL, there is a fixed minimum amount of shader variables, from which you can assume that each spec-conformant implementation will support it. To be more precise, the GLSL ES spec defines minimum numbers of vec4 registers for uniform vectors in vertex and fragment shaders, along with a simple packing algorithm for arranging shader variables in those registers.
For our example application with its very simple shading, the only critical part to check is the vertex shader, and the corresponding limit to check against is MAX_VERTEX_UNIFORM_VECTORS, which must at least be 128 according to the spec. The vertex shader from the batched demo contains the following variables:
- uniform mat4 u_mvpMat[16]
- uniform mat4 u_normalMat[16]
The two variables are arrays of type mat4, and each array element will be packed into four subsequent vec4 registers. Therefore, the 16 model-view-projection matrices and the 16 normal matrices together consume 128 registers, which is exactly the minimum.
The batched rendering demo actually tries to put as many objects as possible into each batch, depending on your GPU - you might have noticed the values showing the batch size, at the bottom of the demo page. Given the two matrix arrays inside the vertex shader, this value is simply computed as MAX_VERTEX_UNIFORM_VECTORS / (2*4). Still, although my test GPU was able to draw 128 teapots in one batch instead of just 16, I did not observe any significant speedup when switching to that number. This supports the assumption that the bottleneck of the batched version is not the number of draw calls any more, even with 16 objects per batch (instead, I think it could be vertex processing).
So, when would it make sense to use batched rendering?
The teapot example was obviously not a real-world application, so the question would be which kinds of applications could really benefit from batched rendering in a similar way. If there is hardware support for instanced rendering, and if you just want to draw the same object a lot of times at different places, you maybe don't need to batch any draws together at all. In contrast, if you have many parts, which are all unique, batched rendering is probably the best thing you can do to speed up your renderer. There are also applications where you have a lot of small parts in your input data set, but you don't need to address them separately during runtime. In that case, where you would want to pick, transform or hide either the whole bunch of parts or none of them, you can also batch them all together offline in a preprocessing step, and use a simple renderer without online batching.
What's next?

Looking at the demo, there are some open points that would be important if one would try to integrate the proposed concept into an engine. For the sake of simplicity, I did not use indexed rendering (as it requires adapting indices when batching meshes together) - this was also due to my very minimalistic, basic C++ OBJ converter that I used. It simply loads a triangulated file and writes the triangles' vertex positions and normals to a binary file, using an unsigned byte for each coordinate. The original bounding box is then printed to the command line, and I hard-coded it into the renderer, as it is only drawing teapots anyway.
Next time, I would also not use the J3DI math library again (at the time I wrote the demo I just randomly picked the first one from some public WebGL example) - tojis gl-matrix library is a much better (and faster) alternative, for instance.
Another thing that could be optimized is the number of texture switches. Since each batch uses an own texture to store the colors of the objects, each draw comes along with a texture switch, which is a state change that should be avoided, if possible. Therefore, an optimization could be to use one global texture instead (or a few ones, depending on texture size limitations, and depending on the number of objects).The only purpose of the button for highlighting a single random teapot out of a batch was to demonstrate that this is still possible, although we have batched things together. After a global, random teapot index has been chosen, this index is mapped to the corresponding batch, and then to an offset inside that batch. In a real application, you would likely prefer to directly pick objects with the mouse instead. A good way to provide this feature is to render unique scene object IDs to an offscreen picking buffer. The corresponding object ID for the clicked pixel can then simply be read from this buffer. For this technique, we would need another variable in addition to the idoffset in the current batch, which could be called baseid, for example. This base ID would be a per-batch uniform value, allowing to map the local IDs of objects inside the batch to global IDs, when rendering to the picking buffer (with globalID = baseID + IDOffset).
Finally, within a real WebGL rendering engine, there are usually also other techniques in use that reduce the number of draw calls per frame, such as view frustum culling or small feature culling. These techniques naturally conflict with batching, as the culling efficiency is maximized when there are a lot of small, individual objects, each with a perfectly fitting bounding box. Batching, in contrast, merges objects together, thereby decreasing the granularity for culling. One way to mitigate against this problem would be to batch objects together based on their position in space. One could, for example, create a spatial structure, such as an octree or a bounding interval hierarchy. The objects inside the leaves could then be recursively accumulated (batched) into their parent nodes, until a minimum threshold for the number of triangles or vertices within each batch has been reached.
If you have read until here - congratulations, you made it! :-) As always, if you have any comments or suggestions, or if you discover any mistakes or inaccuracies, please feel free to write me an email. Thanks a lot for your attention!
Other Articles